“大数据杀熟”并非一个新鲜玩意了,但它所引起的重视远远不够。
我们希望通过采访专业的程序员、算法工程师、法律专家等人士来找到哪怕一丝的使用技巧和方式,来避开所谓的“大数据杀熟”。让人难过的是,得到的回复大多是“没办法”“不可能”“看运气”“维权渺茫”。
这只是一个结论。当我们深入研究了“大数据杀熟”过程、维权方式和途径之后,生出一种“人为刀俎,我为鱼肉”的无力感,也压着被大数据“杀熟”的每一个人。
那么大数据背后的技术路径是怎样的?这种做法背后隐藏的商业逻辑又成为了谁的“致富经”呢?
大数据这样杀熟
“大数据杀熟”,对于每个活在互联网世界里的人都不是个陌生词汇,据公开资料记载,“大数据杀熟”是在2018年被广泛关注和报道的。
不过,我的一位程序员朋友告诉我,早在2017年,他就在某打车软件上经历了大数据杀熟:“比如我和我媳妇同时打车,同时发起,同样的起止点,我的定价每次都会贵一些,因为我每天都要打这个路线的车,我媳妇是偶尔会打,就感觉是分析出来熟客吃定的感觉。”
无独有偶。
我身边的同事也分享了她被大数据杀熟的经历,巧合的是,她同样也是在使用打车软件。
“2016年左右,我家住在丰台区的怡海花园,每天到海淀的上班距离很固定,那时候最开始打车每次只需要20多块钱,但是差不多就在三个月时间内,就涨到了50多。”
关于这种情况,滴滴总裁曾坚决表示“滴滴出行不存在大数据杀熟的行为。”
但可以肯定的是,真实存在的大数据杀熟要比我们已知的出现时间更早。
在目前市面上已有的报道中,并不缺乏这样的案例,甚至在刚刚过去的双十一,这样的戏码也依旧在上演。
据央视报道,北京的韩女士使用手机在某电商平台购物时,中途错用了另一部手机结账,却意外发现,同一商家的同样一件商品,注册至今12年、经常使用、总计消费近26万元的高级会员账号,反而比注册至今5年多、很少使用、总计消费2400多元的普通账号,价格贵了25块钱。

仔细对比才发现,原来普通账号页面多出来一张“满69减25”的优惠券。韩女士认为自己遇到了大数据“杀熟”。
那么大数据背后的杀熟原理究竟是怎样的呢?总结来看,简单的流程如下图所示。
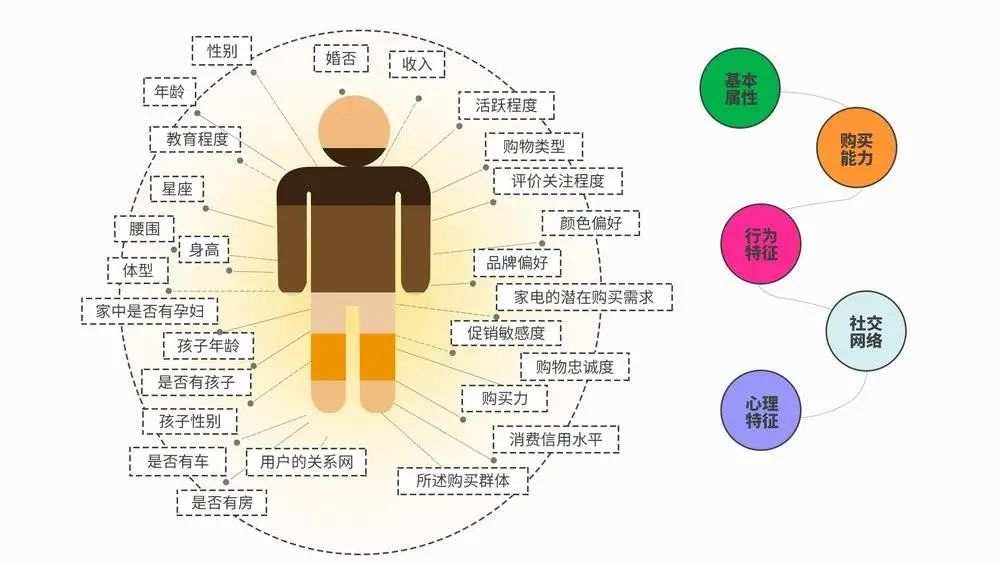
图片来源:CSDN博客
如果非要给“大数据杀熟”一个定义,就是“老客户看到的价格会高于新用户”。而企业这样做的目的,主要是为了增加新用户的粘性。
其实在现实生活中,我们会遭遇大数据杀熟的移动应用无非是两种:
一是使用在线旅游类的APP,比如携程,去哪儿,飞猪等;另一种则是使用电商类APP,比如淘宝,京东,美团等。而在电商类APP中,具体在什么时间对你进行杀熟,又要分平时消费与节假日促销两种情况。
这里需要指出,在任何场景下,大数据杀熟一定是基于你的行为习惯来进行分析的。
所以,就有了这样一个事实,我们通过APP进行的大部分行为都在被实时获取,它们会变成一个个小标签,标记我们的同时,也成为了商家算计我们的利器。
以在OTA软件为例,这些标签中,除了基本的男女,地区,是否使用苹果手机之外,还会有你几点几分浏览了什么商品,看了多久,价位如何等等。
简言之,就是几乎每个会影响你消费的行为都在被标记。
但一位程序员告诉我们,在电商场景中,还存在另一种“杀熟”现象。
她举例称:假如我平时浏览服装和宠物用品时间比较多,那么某宝在给我推荐这类产品时,需要推荐相似但性价比高的产品,因为花费了较多时间,会产生“价格敏感”——因为常用,我会对这些商品价格区间更为熟稔。
反之,当我突然开始浏览平时不怎么看的产品,比如机械键盘,男生球鞋,且浏览时间不长,那么算法就会倾向于推荐价格较高的产品。
而原因也呼之欲出——我不熟。
几年前,在一次采访中阿里云的程序员曾满脸自豪地讲到,“我们现在已经能够做到全中国几亿人口的淘宝界面都是不一样的,而且几乎做到了秒级更新。”
而那个阶段也正是阿里发力“千人千面”的新零售的高潮,这里的“千人千面”可以简单地理解为每个人的淘宝界面都不一样,都是基于算法进行“量身定制”的。
也正是因为所谓的“千人千面”的存在,所以当我在这次采访中,追问到底我们什么样的行为关键词会触发大数据杀熟机制时,并没有得到一个唯一的答案。
因为我们每一个人,都被一套特定的算法所“操纵”。
一位多年的行业从业人员告诉我:“首先,行为关键词属于算法的一部分,而算法对于公司来讲属于商业机密;其次,具体的测算方式不唯一,每个人的行为都会被进行无数次分析,然后进行个性化推荐,效果最好的才会被采用。”
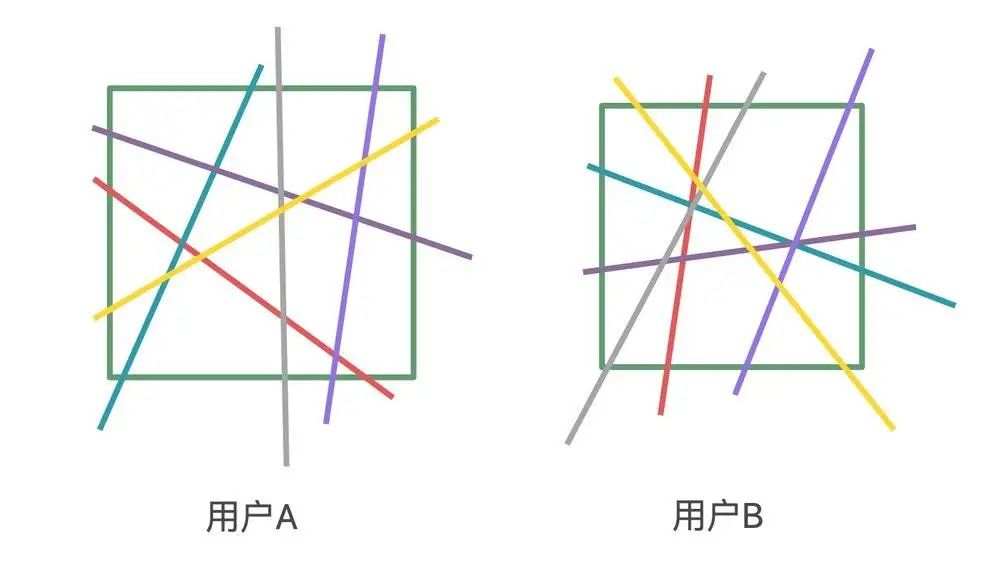
为了更形象地解释,他还举了这样一个例子:假设我们每个人的数据是一个面积不同的正方形,我们要在正方形中找到一个特定最佳的面积值。
我们需要在这个正方形中从各个角度画无数条线,直到找到那个最优解。而这条带来最优解的线就是“专属于你的算法”。
对于用户A,可能紫色线是最优解,而对于用户B,可能黄色的是最优解。
不过,一个很有意思的特殊案例也在最近出现了,它证明了“大数据杀熟”不能被完全判定为“不利于消费者的涨价行为”。
今年十一期间,电影《夺冠》上映。出于娱乐的心态,我一个朋友购买了电影票,但一刷之后,她备受情节鼓舞。于是在接下来的一周内,她又去同一影院刷了三次。
在这期间,戏剧性的一幕发生了,她发现自己每次买票都比上一次便宜。第一次价格是将近100元,但四刷的电影票只需要26元。
当然,被大数据杀熟而减价的事情肯定并不常见,因为我们也无法判断这是否是影院为了市场回暖而采取的特殊降价举措。
但从商家来讲,降低了客单价,同时又增加了用户粘性,也不失为一个经商之道。
低成本,高回报
了解这样一套操作流程后,不知道大家是否跟我一样,会考虑到大数据杀熟的成本问题,毕竟这样看似复杂多变而又个性化的操作,显然不是一日之功。
于是,我又把这个问题抛给了算法工程师们,以期大数据技术在操作难度和成本上为我们的权益上一道锁。
然而,我的天真想法却再一次落空。
“搭建企业大数据系统后台当然是需要花费一定时间和金钱,但搭建系统的目的是为了APP的正常使用,而‘杀熟’,恰好是可以捎带上的一个能力。”一位在多个OTA平台工作的算法工程师告诉了我真相。
换句话说,“我们被杀熟”只是随着数据、系统与产品愈加丰满而出现的一个附加能力,但没想到让企业取得了意想不到的效果。
“没你想象得那么难,打标签这项工作不需要付出很多成本。而至于怎么来杀熟,那只是用样本验证模型的事情。”另一位产品负责人补充道。
成本如此之低,那回报又是如何呢?
很遗憾我们并没有从国内的企业方获得这样的相关估算,不过曾有人为Netflix算过这样一笔账,或许能带给我们一些启示。
根据美国布兰戴斯大学经济学系助理教授Benjamin Shiller,基于Netflix的研究发现,使用传统人口统计资料的个性化定价方法,可以使Netflix增加0.3%的利润,但根据用户网络浏览历史,使用机器学习技术,来估算用户愿意支付的最高价格,可以使 Netflix 的利润增加14.55% 。
当然,这也只是冰山一角。
虽然很不愿意承认,但是我国的数据隐私保护意识自互联网时代之初,就十分一言难尽。所以我们有理由推测,用更多数据训练出来的中国式推荐算法,为企业带来的营收增长幅度要远超Netflix。
另外,还有一个最近被热议的“带头盔”看房的事件。据报道,目前很多售楼部都安装了类似监控设备的人脸识别系统。
这套系统主要是用来采集潜在购房者的面部信息,一来记录该购房者是自己走进售楼部还是被中介引导走进售楼部,二来是记录购房者进来的次数。
而记录这些信息的原因则在于,被中介引导进门的购房者和第一次进售楼处并下单的购房者,能够享受更多的优惠。
所以,大数据杀熟从商业层面也为企业带来了稳定可靠的收入,或许这也是让这些APP戒不掉大数据杀熟的根本原因,毕竟在商言商,谁不想赚个钵满盆满。
维权难上加难
当大数据杀熟成了互联网消费中的顽疾,除了引发全民的关注度持续高涨,大数据杀熟事件的频发也带来了司法部门的关注。
据公开资料显示,为了治理大数据杀熟行为,司法部门也及时拟定了法律条文,包括但不限于以下内容:

当普通大众有了这样的维权武器。那些站在上帝视角的企业也纷纷低下了高傲的头颅,在被发现对用户进行大数据杀熟行为后,他们一个接一个地发布了否认声明。

当然,他们也并没有只是在口头上下功夫。据知情人士透露,在大数据杀熟相关法律出台之后,各大APP会把产品的真实价格显示给用户,只不过这样的真实价格基本躲在十几页甚至几十页之后。
而这样的擦边球做法也无形中增加了消费者维权的难度。
让人有些无奈的是,拿十月份刚刚出台的在线旅游处理办法来看,消费者维权,企业最高只需要支付50万的赔偿金。这样的处罚程度,对动辄几十亿,上百亿市值的企业来说,简直是九牛一毛。
更何况,现实中能够真正去花费时间、精力去维权的人又少之又少,其他的绝大部分人则会选择无奈摇头,自认倒霉。
上海市新闵律师事务所高级合伙人庄帆律师的真实体会也正好证实了我们的看法。他表示,从他的经历来看,因被大数据杀熟而维权的案例市面上其实寥寥无几。
他举例称,由于律师是一个出差频繁的职业,他和他的同行经常要定机票和酒店,正是如此,也都或多或少,也有过被“杀熟”的经历。
“大家顶多把自己的经历发到群里,抱怨几句,几乎没人去真正地维权,一来,我们明白取证太难,二来,需要付出很多时间成本。”庄帆说。
另外,他还指出了另一个糟心的事实:“连我们这些懂法律的人,都放弃了维权,可见普通人的维权意愿也不会太强,如此一来,就助长了这不良的风气。”
学会了算法,丢掉了信任
如今看来,在商业利益和用户信任之间,国内精明的商人们肯定会选择前者。但如果长此以往,这样聪明的算法又真正算计了谁呢?
值得欣慰的是,现在国家监管层面已经开始在互联网领域推出了反垄断法。
11月10日上午,国家市场监管总局发布《关于平台经济领域的反垄断指南(征求意见稿)》公开征求意见。
其中,互联网平台基于大数据和算法技术优势实行的某些交易行为,也需警惕是否构成“无正当理由对交易条件相同的交易相对人实施差别待遇,排除、限制市场竞争”。
其中,在分析是否构成差别待遇时,可以考虑的因素包括:根据交易相对人的支付能力、消费偏好、使用习惯等,实行差异性交易价格或者其他交易条件等。也就是说”二选一和大数据杀熟或被认定垄断。”
我们一直清楚技术具有两面性,但“黑暗面”却似乎在国内被物尽其用的更加彻底。究其原因,企业的趋利性、法律的漠视、个体的默认,没有一方可以免于责任,置身事外。
水能载舟,亦能覆舟。
没有人能永远拥有行业垄断之势,商家丢掉客户的信任与客户流失并无二致。而已经在中国几亿网民身上尝尽了甜头的互联网与技术巨头们,相信会在某一天因我们的信任而付出有偿的代价。
文章来源虎嗅,版权归原作者所有,如有侵权请联系本人删除。
Tuyên bố miễn trừ trách nhiệm: Quan điểm được trình bày hoàn toàn là của tác giả và không đại diện cho quan điểm chính thức của Followme. Followme không chịu trách nhiệm về tính chính xác, đầy đủ hoặc độ tin cậy của thông tin được cung cấp và không chịu trách nhiệm cho bất kỳ hành động nào được thực hiện dựa trên nội dung, trừ khi được nêu rõ bằng văn bản.

Để lại tin nhắn của bạn ngay bây giờ